

Building Smart Mock: An AI-Powered API Mock Server with Spring Boot and Ollama

APIs are everywhere, but mocking them effectively is still a pain for many developers. Traditional mock servers often require manual configuration, static responses, and considerable time to keep them in sync with changing specifications.
Over the weekend, I worked on a project called Smart Mock, which aims to change that. It’s an AI-powered API mock server built with Spring Boot, Ollama, and LangChain4j. Instead of serving hardcoded responses, it uses an LLM to generate realistic, context-aware mock data directly from your OpenAPI specifications. This makes it perfect for rapid prototyping, testing, and exploring APIs without waiting for the backend to be ready.
In this guide, I’ll walk you through:
Setting up Smart Mock locally
Understanding its architecture
Exploring the intelligent response pipeline
Running real-world usage examples
By the end, you’ll have a fully working AI-powered mock server running on your machine, ready to supercharge your development workflow.
Getting Started
Prerequisites
Java 21+
Maven 3.6+
Ollama (for LLM support)
# Start Ollama with your preferred model
ollama pull codellama:7b
ollama serve
# Clone and run Smart Mock
git clone https://github.com/rokon12/smart-mock.git
cd smart-mock
./mvnw spring-boot:run
# Open http://localhost:8080Configuration
Configure via environment variables or application.yml:
ollama:
base-url: http://localhost:11434
model-name: llama3.1:8b
temperature: 0.6
timeout: 60
cache:
max-size: 1000
expire-minutes: 15If you have a new idea, please contribute! And if you find this project useful, consider giving it a ⭐ on GitHub—it helps others discover it.
Using the Web Interface
Once Smart Mock is running, open your browser and navigate to
http://localhost:8080
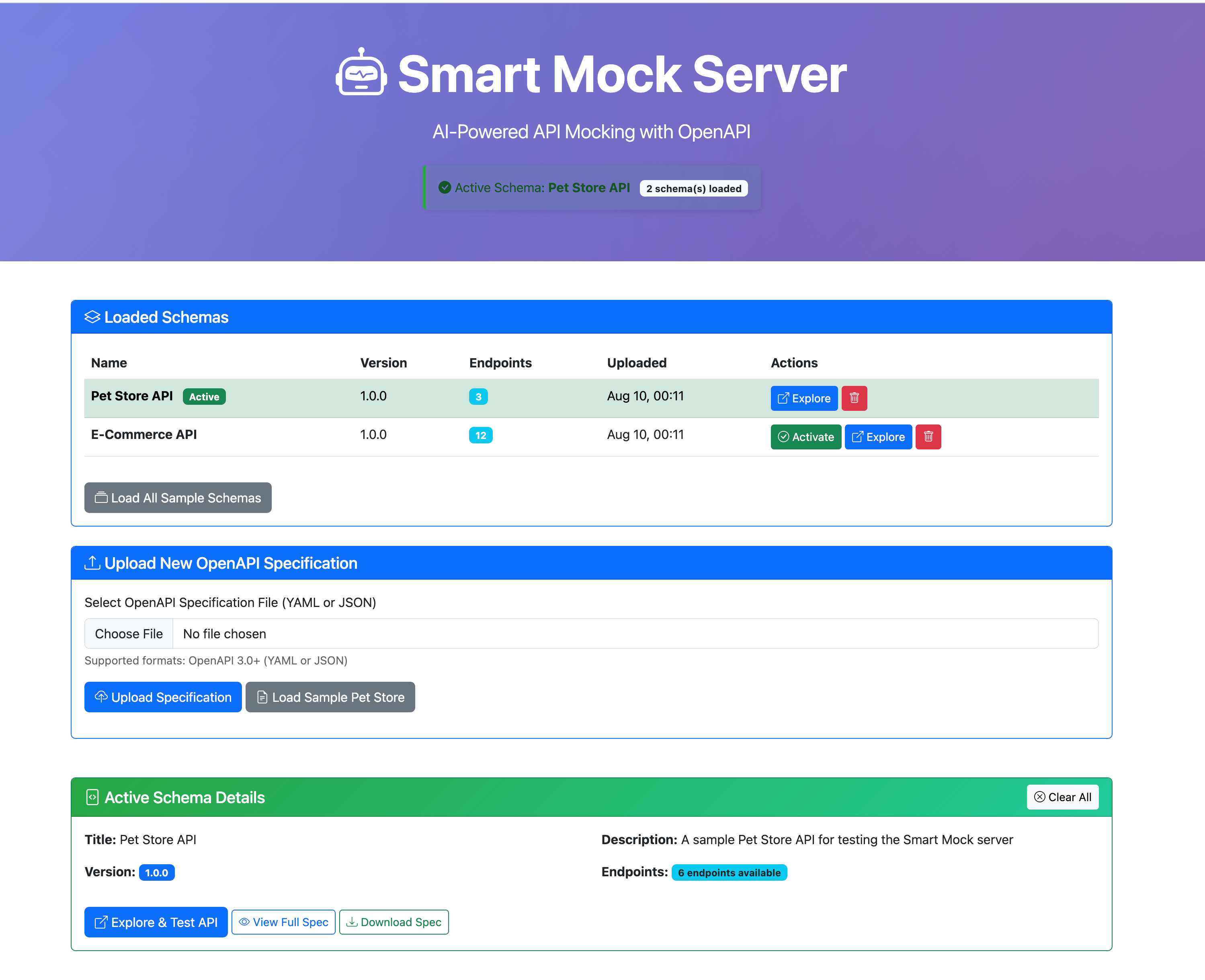
You’ll see the Smart Mock dashboard:
From here you can:
Load the samples to try out the features instantly.
Upload your own OpenAPI specification (YAML).
Explore endpoints directly from the UI with “Explore & Test API.”
The interface allows you to switch between loaded schemas, activate one as the current mock API, and immediately test it without any extra configuration.
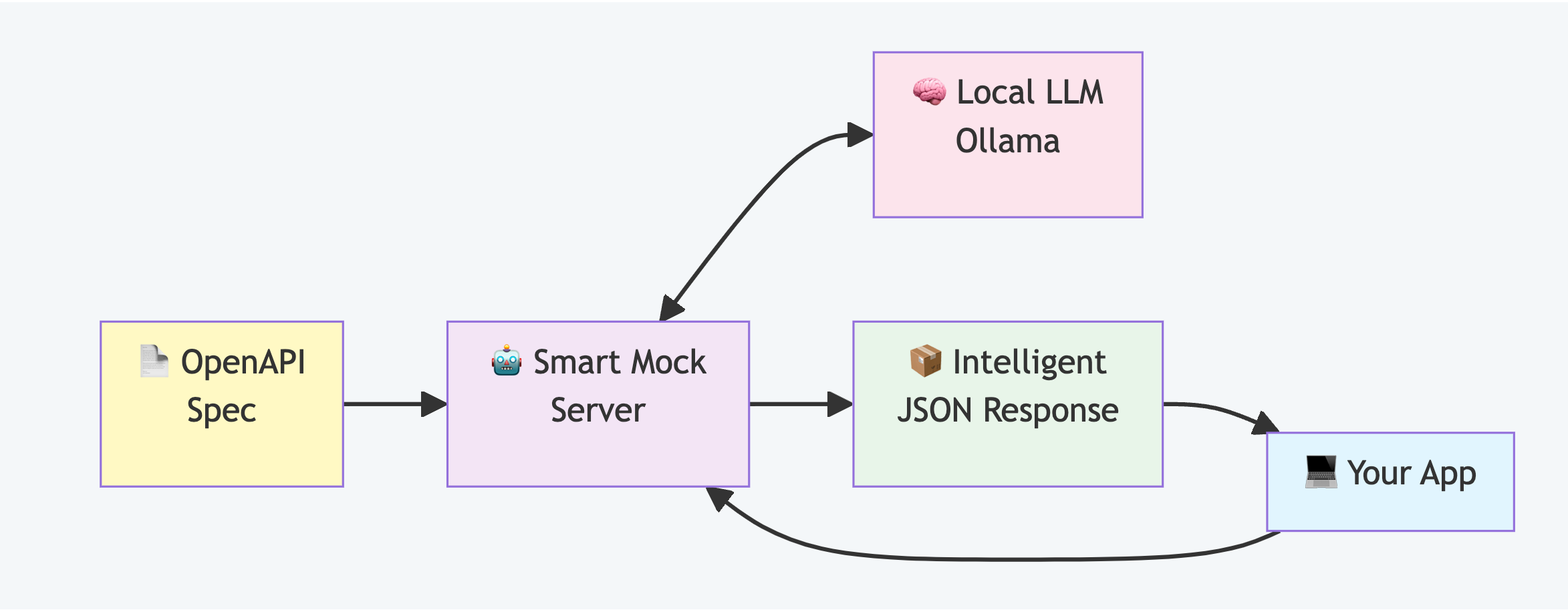
How Smart Mock Works
The workflow is straightforward:
Upload your OpenAPI specification
The server creates all endpoints automatically
Each request receives an AI-generated response matching your schema
Control behaviour through request headers (scenarios, seeds, latency)
Test endpoints through an integrated Swagger UI
Technical Architecture
Core Dependencies
Smart Mock uses three main technologies:
Spring Boot for API development
LangChain4j for LLM integration
Ollama for local LLM hosting (no API keys required)
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>1.3.0</version>
</dependency>Architecture
Spring Boot Web – API handling
OpenAPI Parser – Ingests and indexes specifications
LangChain4j + Ollama – Local LLM response generation
Caffeine Cache – Fast in-memory caching
JSON Schema Validator – Enforces schema compliance
High-Level Concept
Simple Flow Diagram
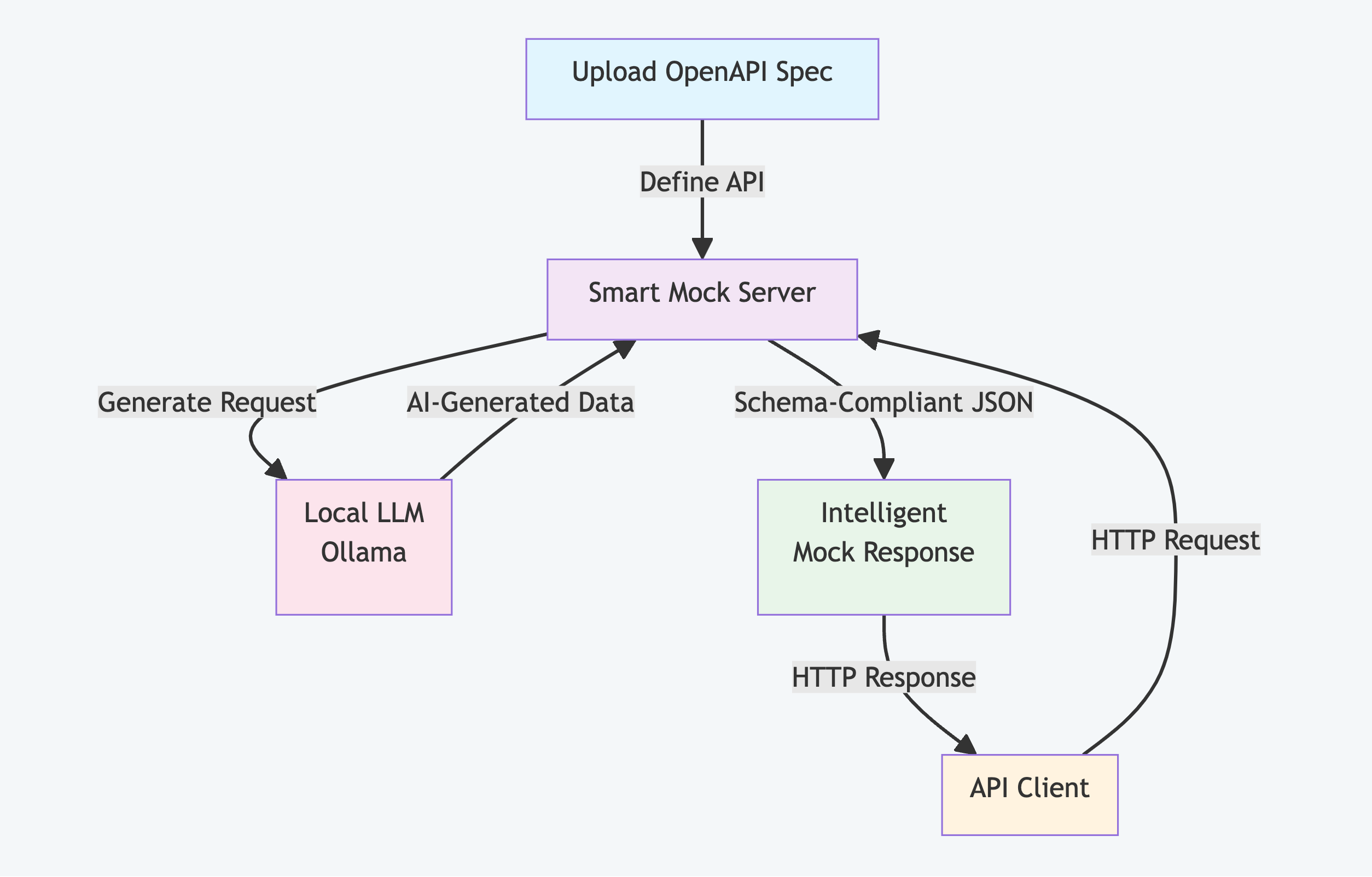
Implementation Details
Dynamic Endpoint Creation
Spring's RequestMappingHandlerMapping doesn't support runtime endpoint registration easily. Smart Mock uses a catch-all controller instead:
@RestController
@RequestMapping("/mock")
public class MockController {
@RequestMapping("/**")
public ResponseEntity<?> handleMockRequest(
HttpServletRequest request,
@RequestBody(required = false) String body,
@RequestHeader Map<String, String> headers) {
String path = extractPath(request);
String method = request.getMethod();
return openApiIndex.match(method, path)
.map(endpoint -> generateResponse(endpoint, headers, body))
.orElse(ResponseEntity.notFound().build());
}
}
This controller intercepts all /mock requests and matches them against the loaded OpenAPI specification.
Response Generation Pipeline
Smart Mock generates responses through five stages:
Schema Extraction: Extract the expected response schema from OpenAPI
Prompt Construction: Build a detailed prompt for the LLM
LLM Generation: Use Ollama to generate a response
Validation & Repair: Validate against JSON Schema and repair if needed
Response Delivery: Return the validated response
public class ResponsePlanner {
private static final String PROMPT_TEMPLATE = """
Generate a realistic JSON response for this API endpoint:
Endpoint: {} {}
Description: {}
Scenario: {}
Required Response Schema:
{}
Requirements:
1. Generate realistic, contextual data
2. Follow the exact schema structure
3. Use appropriate data types
4. Consider the scenario: {}
Respond with ONLY valid JSON, no explanation.
""";
public String generateResponse(Endpoint endpoint, Scenario scenario) {
String prompt = buildPrompt(endpoint, scenario);
String response = languageModel.generate(prompt);
return validateAndRepair(response, endpoint.getSchema());
}
}Scenario-Based Testing
Real APIs return different responses based on conditions. Smart Mock simulates this through scenario headers:
# Happy path
curl -X 'GET' \
'http://localhost:8080/mock/pets?limit=10' \
-H 'accept: application/json'\
-H 'X-Mock-Scenario: happy'
# Edge case with minimal data
curl -X 'GET' \
'http://localhost:8080/mock/pets?limit=10' \
-H 'accept: application/json'\
-H 'X-Mock-Scenario: edge'
# Validation errors
curl -X POST 'http://localhost:8080/mock/pets' \
-H 'Content-Type: application/json' \
-H 'X-Mock-Scenario: invalid' \
-d '{"name": "", "category": "invalid_type"}'
# Server errors
curl -X GET 'http://localhost:8080/mock/pets' \
-H 'X-Mock-Scenario: server-error'
# Test rate limiting (429 Too Many Requests)
curl -i -X GET 'http://localhost:8080/mock/pets' \
-H 'X-Mock-Scenario: rate-limit'Each scenario modifies the LLM prompt to generate appropriate responses for different test conditions.
Deterministic Responses
Integration tests require predictable responses. Smart Mock provides deterministic generation through seeds:
# Same seed always returns identical response
curl -s -X 'GET' 'http://localhost:8080/mock/users?page=1&size=20' -H 'X-Mock-Seed: unique-seed-xyz-791' | jqCombined with Caffeine caching, this ensures fast and predictable test execution.
Usage Examples
Upload an OpenAPI Specification
Start with a standard OpenAPI specification:
openapi: 3.0.0
info:
title: Pet Store API
version: 1.0.0
paths:
/pets:
get:
summary: List all pets
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Pet'
Receive Intelligent Responses
$ curl http://localhost:8080/mock/pets
[
{
"id": 1,
"name": "Max",
"category": "dog",
"status": "available",
"tags": ["friendly", "trained", "vaccinated"],
"photoUrls": ["https://example.com/photos/max1.jpg"],
"createdAt": "2024-01-15T08:30:00Z"
},
{
"id": 2,
"name": "Whiskers",
"category": "cat",
"status": "available",
"tags": ["playful", "indoor"],
"photoUrls": ["https://example.com/photos/whiskers1.jpg"],
"createdAt": "2024-01-14T14:20:00Z"
}
]Test Edge Cases
$ curl -H "X-Mock-Scenario: edge" http://localhost:8080/mock/pets
[] # Empty array for edge case
$ curl -H "X-Mock-Scenario: server-error" http://localhost:8080/mock/pets
{
"error": "Internal Server Error",
"message": "Database connection timeout",
"timestamp": "2024-01-20T10:15:30Z"
}Interactive API Exploration
Navigate to http://localhost:8080/swagger-ui.html to see complete API documentation with interactive testing capabilities for each endpoint.
Key Insights
Local LLMs Perform Well
Ollama with models like CodeLlama or Mistral generates contextually appropriate responses. I was pleasantly surprised by how well local models handled API response generation. Running everything locally provides privacy benefits and eliminates API key management.
Prompt Structure Matters
Response quality correlates directly with prompt specificity. Structured prompts with clear requirements produce better results than vague instructions.
Always Validate LLM Output
LLM responses require validation. Smart Mock implements fallback mechanisms and validation loops to ensure reliable operation.
Cache Aggressively
LLM inference consumes computational resources. Caching, particularly for deterministic scenarios using seeds, improves performance significantly.
Future Enhancements
Several features could extend Smart Mock's capabilities:
State Management: Maintain state between requests for realistic workflows
GraphQL Support: Extend beyond REST APIs
Response Learning: Learn from real API responses to improve generation
Performance Metrics: Built-in latency and throughput testing
Cloud Deployment: Simplified deployment and sharing of mock servers
Conclusion
Smart Mock streamlines API development by removing the bottleneck of unavailable or incomplete backends. With intelligent, schema-compliant, and scenario-driven responses generated locally by Ollama, it enables faster iteration, more robust testing, and greater flexibility. Whether for prototyping, integration testing, or exploring edge cases, Smart Mock helps teams deliver with confidence while keeping full control of their data and infrastructure.